🌗ATC’19 SILK/TOCS’20 SILK+
type
Post
status
Published
date
Mar 14, 2023
slug
silk
summary
ATC’19 SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores
tags
LSM
Key-Value
Paper
Write
category
论文分享
icon
password
Property
Feb 6, 2025 05:45 AM
References
Blog


原资料
- SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores


SILK-USENIXATC2019
theoanab • Updated Mar 23, 2025
Abstract
- 已经有广泛的文献证明,LSM Comapction 严重影响了吞吐量,现有的一些优化方案有:
- 限制 Compactions 和 Flushes 的速率
- 选择合适的 Compaction 策略(收益最大化)
- 通过所谓的碎片化 LSMs 将 Compaction 限制到最高级别(如 PebblesDB 的 FLSM)
- 本文更关注延迟,因为现有的优化吞吐量的方案并不会解决长尾问题,反而可能会加剧该现象。
- 造成长尾的根本原因是客户端写、flush、compaction 操作之间的干扰。尾延迟的另一个主要原因是工作负载在操作组合和项目大小方面的异构性,即少数计算量较大的请求会拖慢绝大多数较小的请求。
- 所以本文提出了一个 I/O 调度器来减少干扰:
- 在低负载期间,机会地将更多带宽分配给内部操作
- 优先执行 flush 和较低级别的 compactions 操作
- 根据请求大小和数据访问路径分离客户端请求
- 基于 RocksDB 的 SILK,测试表明相比于 RocksDB 和 TRIAD 尾延迟降低了两个数量级,且未对性能产生任何负面影响。
Introduction
- 对延迟敏感的应用程序需要能够提供低延迟和可预测吞吐量的数据平台。尾延迟尤为重要,因为应用程序经常会出现高扇出查询,其总体延迟取决于最慢回复的响应时间。日志结构合并键值存储(LSM KV),如 RocksDB[26]、LevelDB[18] 和 Cassandra[41],在生产环境中被广泛采用,为这类对延迟敏感的应用程序提供主存之外的存储,特别是对于写入密集型工作负载。在 Nutanix,我们使用 LSM KV 来存储核心企业平台的元数据,该平台为数千名客户提供PB级的存储容量。
- 键值存储支持一系列客户端操作,如 Get()、Update() 和 Scan(),用于存储和检索数据。日志结构合并键值存储(LSM KV)通过在内存缓冲区中吸收更新来追求良好的更新性能 [50, 51]。存储设备上维护着一种树状结构。除了客户端操作,LSM KV 还执行两种类型的内部操作:刷新,即将内存缓冲区的内容持久化到磁盘;以及 Compaction,即将树状结构中较低层级的数据合并到较高层级。
- 在本文中,我们证明了在当前最先进的日志结构合并键值存储(LSM KV)中,尾延迟可能会非常高,尤其是在客户端写入负载沉重且变化不定的情况下。我们引入了针对 LSM KV 的 I/O 调度器概念。我们在 RocksDB 中实现了这个 I/O 调度器,结果显示尾延迟最多可提升两个数量级。
- 我们的工作补充了近期许多致力于提高日志结构合并键值存储(LSM KV)客户端吞吐量的研究(例如[5, 32, 38, 45, 47, 52, 53, 57, 58])。通过降低内部操作成本可以提高客户端吞吐量,但这不足以降低尾延迟。内部操作仍然是必要的,在内部操作进行期间到达的客户端操作会因与这些内部任务的干扰而经历更高的延迟。虽然内部操作的数量可能会减少,成本也可能降低,从而降低延迟尖峰出现的概率,但在实际情况中,它们发生的频率仍然足以影响延迟分布的高阶百分位数,尤其是在客户端负载突发的情况下。
- 有人可能一开始会认为,像在生产系统中常见的那样,限制分配给内部操作的 I/O 带宽,就能避免因内部工作与客户端负载之间的干扰而导致的延迟峰值。然而,仔细研究后我们发现并非如此。
- 举个简单的例子,假设客户端突发大量写入操作,引发大量刷新操作。如果同时进行多个 Compaction 操作,刷新操作就必须与 Compaction 操作共享有限的带宽,进而导致刷新速度变慢。这会使内存组件被填满,从而阻塞后续的写入操作,最终产生延迟峰值。
- 限制 Compaction 操作的速率也不够,因为这可能会导致树状结构的最低层级被填满,使刷新操作停滞,进而使写入操作也停滞。
- 这些以及其他观察结果让我们得出结论:降低内部操作成本或限制其带宽分配不足以避免延迟峰值,相反,客户端负载与不同内部操作带来的负载之间,从根本上需要进行协调。
- 尾延迟的另一个主要来源与客户端负载的内在特性有关:
- 针对较大键值(KV)项或跨多个KV项的请求(例如范围扫描)会延迟对延迟敏感的较小请求。这种队头阻塞的发生是由于 LSM KV 的线程架构以及客户端操作类型之间缺乏区分。
- 流行的基准测试,如 YCSB[15]和 db_bench[28],使用固定的 KV 项大小,无法捕捉到这个问题,但在 KV 项大小可变的实际工作负载中,这个问题就会暴露出来。
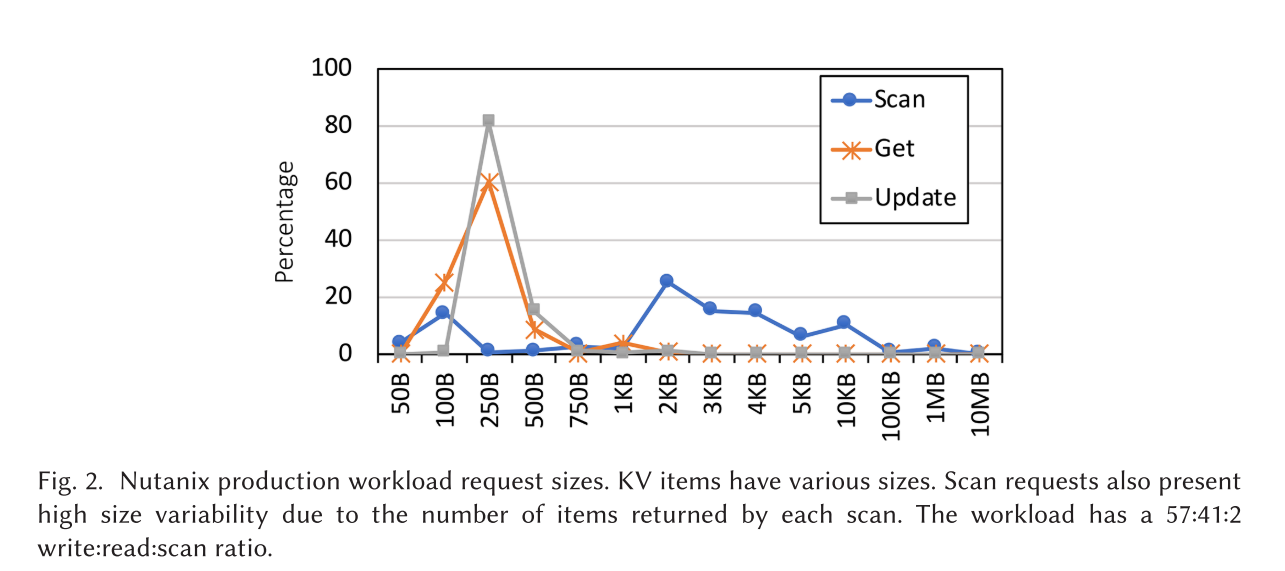
- 例如,有报告称 memcached[48] 中的 KV 项大小存在显著差异:Facebook 的 memcached 池存储的 KV 项大小从几字节到 1MB 不等[4]。在 Wikipedia 和 Flickr 等 KV 部署中也可以看到类似的 KV 项大小差异,其中 KV 项大小范围从 500 字节到1MB[11, 44]。Nutanix 也存在类似的 KV 项大小异质性,在那里,一个 LSM KV 存储被用于元数据管理系统。各种服务会查询这个 KV 存储,它被划分为多个列族,每个列族包含不同类型的信息(即包含不同大小的 KV 项)。
- 为防止尾延迟飙升,我们引入了针对基于日志结构合并(LSM)的键值存储(KV)的 I/O 调度器概念。我们基于 RocksDB 构建了一个新的键值存储 SILK+。SILK+ 中的 I/O 调度器具有以下功能:
- (1)在客户端操作和内部操作之间动态分配带宽;
- (2)优先处理可能阻塞客户端操作的内部操作;
- (3)根据预估的请求处理时间对客户端请求进行分类。
- 虽然可能还有其他技术可以采用,但我们发现这些功能足以在写入密集型工作负载下将尾延迟降低两个数量级,同时对吞吐量和平均延迟没有负面影响。此外,SILK+ 在读取和扫描密集型工作负载中也不会产生明显的负面影响。
贡献
- (1)一项广泛的实证研究,证明了当前日志结构合并键值存储(LSM KV)存在较高的尾延迟。
- (2)引入了针对日志结构合并键值存储(LSM KV)的 I/O 调度器,以及多种有助于在保持良好吞吐量的同时降低尾延迟的调度技术。
- (3)在行业标准的日志结构合并键值存储(LSM KV)(即RocksDB)中,实现了 LSM KV 存储的 I/O 调度器。
- (4)一项实验评估表明,在我们的生产工作负载中,尾延迟最多可提高两个数量级,且对其他性能指标或工作负载没有显著的负面影响。
Background
LSM KV 架构
- 一个日志结构合并键值存储(LSM KV)有三个主要组件:内存组件、磁盘组件和提交日志。我们在图 1 中展示了 LSM KV 存储的架构。
- 内存组件 是一种驻留在主内存中的有序数据结构。它的大小通常较小,大约为几十兆字节。 的作用是临时吸收用户的更新数据。当 被填满时,会被一个新的空组件所取代。然后,旧的内存组件会在后台直接被刷新到 LSM 磁盘组件的第 0 层
- 磁盘组件 被组织成多个层级(、、……、),每一层级的大小都比前一个(较低的)层级大一个可配置的因子(例如 10 倍)。每一层级包含多个有序文件,称为排序字符串表(SSTable)。给定层级上的 SSTable 数量由一个配置参数限制,给定层级中单个文件的最大大小也是如此。()层级上的 SSTable 具有不相交的键范围。 层级允许文件之间的键范围重叠。
- 提交日志 将对 的更新(以小批次形式)存储在稳定存储设备上。 的大小通常为几百兆字节。如果应用程序要求在发生故障时数据可恢复,就会用到它,但它并非必不可少。无论 是否启用,我们在 SILK+ 中提出的技术都适用。

LSM KV 操作
日志结构合并键值存储(LSM KV)实现了两种主要类型的操作,由不同的线程池执行。
- 客户端操作:LSM KV 中的主要客户端操作包括写入(Update(k, v))、读取(Get(k))和范围扫描(Scan(k1, k2)) 。
- Update(k, v) 将值 v 与键 k 关联起来。更新操作被内存组件 吸收,以实现高写入吞吐量。
- Get(k) 返回键 k 的最新值。读取操作首先在 中进行。如果在 中未找到键 k,读取操作会继续在 、、……、 中进行,直到找到键 k。按照设计,对于 的情况,在每个 层级上最多检查一个 SSTable。相反,由于 层级的 SSTable可能包含整个键范围,所以可能需要检查 中的多个SSTable。每个 SSTable 使用布隆过滤器 [10, 34] 来解决这个问题。因此,在实际中,大多数时候在 层级最终只检查一个 SSTable。
- Scan(k1, k2) 返回键范围从 k1 到 k2 的一系列键值对。首先,在 中查询 k1 - k2 范围内的键。然后,按层级向下读取 中可能包含 k1 - k2 范围的 SSTable,直到找到所有的键。
- 客户端操作由一个固定大小的工作线程池按先进先出(FIFO)顺序排队并处理。每个工作线程同步执行请求,需等待正在进行的请求完成后,才能开始下一个请求。像读取和写入这样的基本操作,一旦提交到日志结构合并键值存储(LSM KV),工作线程从逻辑上无法中断并恢复操作。而像扫描这样的复合操作则可以中断并恢复。LSM KV 存储中的工作线程数量取决于硬件规格以及数据存储所支持的并发程度。例如,RocksDB [26] 允许并发读写操作,而 LevelDB [18] 仅支持并发读取和顺序写入。
- 内部操作:LSM KV 将刷新和 Compaction 作为后台操作来实现。刷新操作将内存组件 的内容直接写入到 层。由于刷新速度会影响新内存组件的安装速率,因此内存组件会在不进行额外处理的情况下写入磁盘。结果是, 层允许键范围重叠。Compaction 是清理 LSM 树的操作。它将磁盘组件 中 层的 SSTable 合并到 层具有重叠键范围的 SSTable 中,在此过程中丢弃旧值。当 层的大小超过其最大值时,会从 层中选择一个 SSTable F,并将其合并到 层中与 F 具有重叠键范围的 SSTable 中,其方式类似于归并排序。大多数 LSM KV 存储支持并行 Compaction,但从 $L_0$ 层到 $L_1$ 层的压缩除外,由于 层存在键范围重叠的情况,这部分合并无法并行化。合并操作会通过读取 SSTable 并将新的 SSTable 写入磁盘,从而产生大量的 I/O 开销。
- 系统维护一个内部先进先出(FIFO)工作队列,刷新和合并操作会被放入该队列中。当一个新的内部工作请求进入队列时,它会被放置在内部工作队列的末尾。当内存组件 填满时,刷新操作会被排入队列。合并操作可能会在一次刷新完成后,或者一次合并完成后排入队列。一组内部工作线程负责处理内部工作队列中的请求。在当前的日志结构合并键值存储(LSM KVs)中,只要系统认为为了维护 LSM 树的结构有必要进行内部操作(例如,当某一层达到最大大小或最大文件数量时),就会将内部操作排入队列。
State-of-the-art LSM-based systems
- RocksDB 提供了 RateLimiter 来限制内部操作的I/O带宽。带宽可以设置为固定值,或者 RocksDB 可以按照乘性增加、乘性减少的方式随时间改变带宽 [27]。这种自动调整版本的速率限制器会根据内部工作来适配带宽,当有更多待处理工作时分配更多带宽。
- TRIAD 通过三种技术降低内部操作的开销。
- 第一,TRIAD 将频繁更新的键保存在 中,减少偏态工作负载下的内部工作开销。
- 第二,TRIAD 利用已写入 的数据来改进刷新操作。
- 最后,在磁盘层面,TRIAD 采用基于成本的方法来触发从 到 的压缩操作。只有在键范围有显著重叠时才进行压缩,从而降低 Compaction 操作的频率并分摊其成本。
- PebblesDB[53] 通过使用碎片化的 LSM 树,允许除最高树层之外的所有层存在重叠的键范围,从而避免了合并和重写 SSTable 的大部分压缩开销。PebblesDB 在每一层按键范围对 SSTable 进行排序,并使用称为 “guard” 的特殊指针来指示给定键范围在该层的位置。当某一层的 guard 数量达到阈值时,这些 guard 和相应的键会被移动到下一层,而且大多情况下无需重写 SSTable。只有当 guard 数量达到阈值时,PebblesDB 才会在最高树层进行 Compaction。
Performance requirements for LSM KVs
- (1)低尾部延迟。在LSM键值存储(LSM KVs)为具有高扇出操作的应用程序提供服务的环境中,操作中最慢的响应决定了整个操作的延迟,因此低尾部延迟是一项关键要求[22]。
- (2)可预测的吞吐量。日志结构合并键值存储(LSM KVs)必须在任何时候都能提供与客户端负载相匹配的吞吐量。吞吐量的可变性是 LSM KVs 中一个众所周知的问题,主要源于 LSM 内部操作与客户端请求之间的干扰[32, 42]。
- (3)较小的主内存占用。通常情况下,日志结构合并键值存储(LSM KVs)只是应用程序所访问的一系列广泛服务中的一部分。例如,一个处理元数据的键值存储可以与其他需要大量内存的服务共存于同一台机器上,这使得内存成为一种受限资源。
LSM issues
- 在日志结构合并键值存储(LSM KVs)中,一个常见的问题是,当客户端突发大量写入操作,同时又有长时间运行且资源密集型的压缩任务并行执行时,LSM 的内部工作与客户端操作之间会产生干扰。尽管 LSM 的内部工作会直接影响客户端延迟,但在处理时却未考虑客户端负载情况。例如,大规模的合并操作(如压缩数十GB的数据)可能会在很长一段时间(如数十分钟)内占用很大一部分 I/O 带宽。由此产生的问题是双重的。
- 第一,当刷新操作不能及时进行时,内存组件会被填满,新写入的数据无法被内存组件吸收。
- 第二,从 L0 到 L1 的缓慢 Compaction 会导致 L0 上积累大量的 SSTable。在极端情况下,当 L0 上的 SSTable 数量达到最大值时,这种情况会使整个系统陷入停顿。
- 这两种情况都会导致客户端延迟大幅飙升。
- 队头阻塞问题在内存数据存储的背景下已得到研究。相反,在持久性键值存储(KV)的背景下,它受到的关注较少。原因是在传统的日志结构合并键值存储(LSM KV)中,内部操作的干扰掩盖了工作负载异构性的影响。然而,一旦内部操作的干扰得到缓解,我们发现异构性也成为了 LSM 的一个问题。典型的 LSM KV 工作负载包含对不同大小的键值对(KV item)的读取、写入和扫描操作。例如,图 2 展示了 Nutanix 生产工作负载中键值对的大小分布。据报道,Facebook、维基百科、Flickr 和 Memcachier 的生产工作负载中也存在类似的键值对大小可变性[4, 11, 25, 44]。如上文所述,最先进的 LSM KV 以先到先服务的方式处理客户端操作,这导致小型操作在更耗时的请求之后发生队头阻塞。
Experimental study of tail latency
- 我们进行了广泛的实验研究,以表明行业中使用的成熟技术和最先进的研究系统都无法解决尾延迟问题。
Setup
- YCSB
- update-intensive workload,R:W=50:50, items 1KB (workload A)
- uniform data distribution (便于排除倾斜负载中内存缓存带来的影响)
- 参数:尽可能调了参数
- 参考 RocksDB Tuning Guide
- 参考 PebblesDB
- HW:
- 20-core Intel Xeon (two 10-core 2.8 GHz processors)
- 256 GB of RAM
- 960GB SSD Samsung 843T
- cgroup 限制 1GB 内存使用
- 其他配置:
- 每个实验都包含一个填充阶段,之后按照 Nutanix 生产工作负载,以每秒 18000 次操作(18 Kops/sec)的速率进行读写操作
- 除非特别强调,都没限制内部操作的 I/O 带宽
- 除非特别强调,RocksDB 两个内存组件 128MB each
- 内部操作最大并发数 10
- 延迟每秒测一次,99th 延迟间隔 1s
RocksDB
- 对比对象:开启了 compaction 和 flush 的 RocksDB 和未开启内部操作的 RocksDB
- 关闭 flush 意味着内存组件写满之后直接被 discard,从而实现无需调度内部操作
- 数据存储预先在磁盘上填充了完整的键集,因此,如果有必要,可以通过读取来访问持久性存储
- 结果表明在 50th\90th 延迟方面,两种情况都很少出现 latency spike,但是对于 99th 无内部操作的 RocksDB 基本要少 2-4 个数量级的延迟。
- 尽管在日志结构合并键值存储(LSM KV)中读取和写入的访问路径不同(即写入在内存中完成,而读取通常从持久存储提供数据),但它们同时出现了相同幅度的延迟峰值。
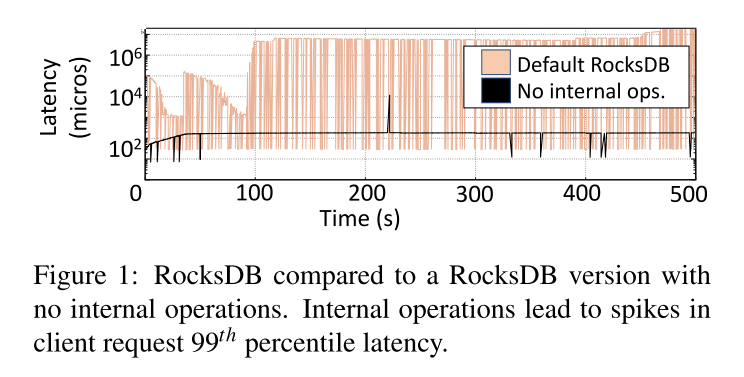
- 原因分析:内存组件填充满了阻塞了写操作,读操作又排队在写之后。
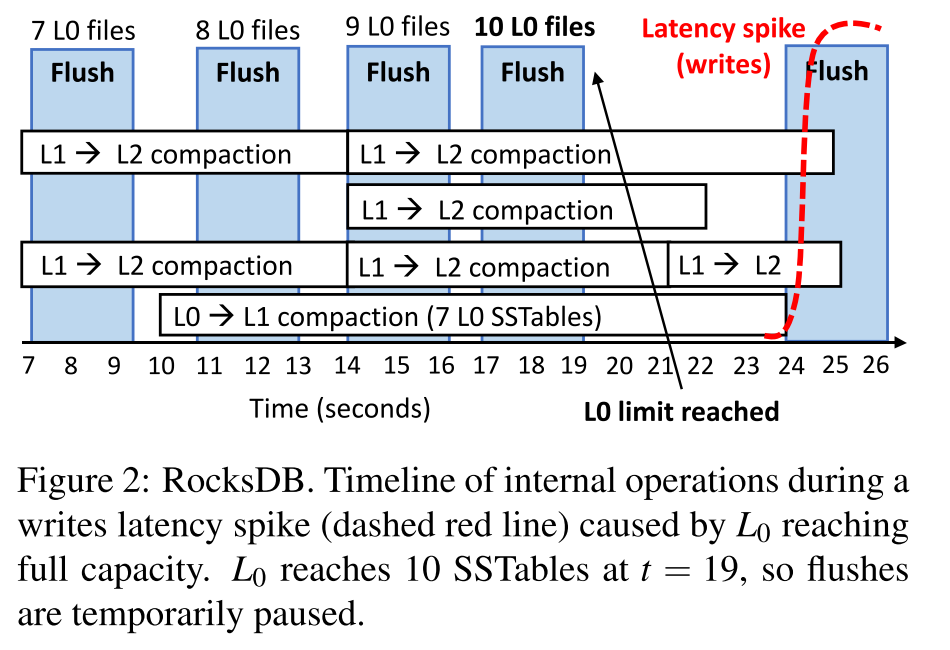
- 原因 1: L0-L1 变慢
- 下图所示即为 write latency spike 的例子。
- 一开始 L1-L2 的 compaction 在并行的执行,然后客户端持续写入,L0 -> L1 也开始执行,但客户端仍然在持续写入,而 L0->L1 没法并行执行,就出现了从 14-23 这段时间内的大量 Compaction 线程执行,但是 L0->L1 只有一个线程执行的情况
- 因为 I/O 资源会被平均分配,所以 L0->L1 Compaction 线程就变相地被减慢了,因此反过来就会造成 flush 操作被临时挂起。
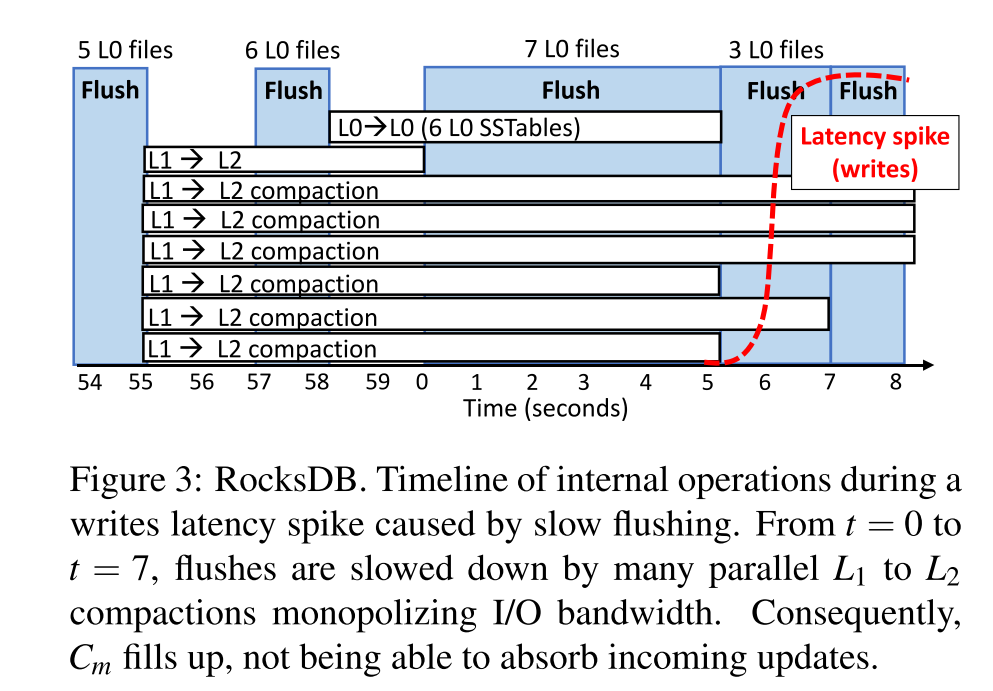
- 原因 2:Flush 变慢
- 下图所示,因为 flush 太慢造成内存组件很快填满,延迟显著增加。
- 从 t=0 开始刷新需要非常长的时间 (5秒,而典型的刷新需要1-2秒)
- 原因是因为这时候恰好很多 Compaction 线程在同时执行,因为有限的可用 I/O 带宽导致 flush 很慢。
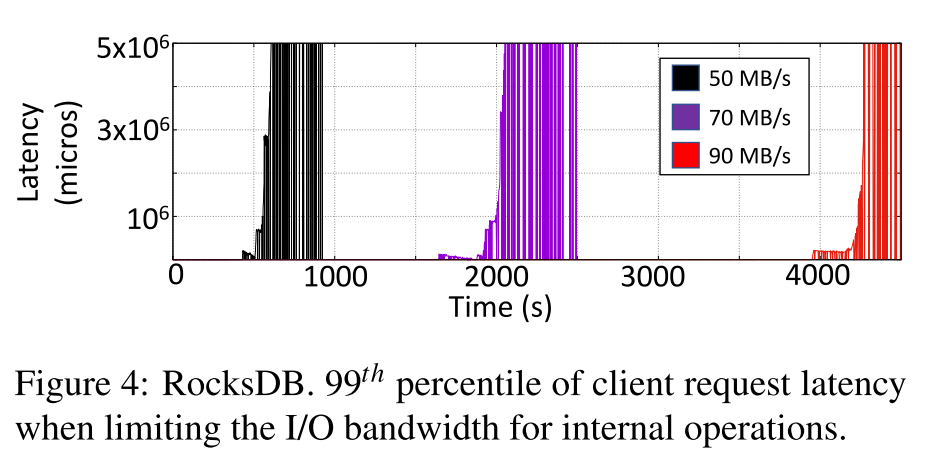
Rate-limited RocksDB
- 对比对象:限制内部操作 I/O 带宽的 RocksDB
- 下图展示了将带宽限制到 50/75/90 MB 时侯的 99th 延迟,为了便于阅读,图中只展示了尾延迟显著恶化的时间点(例如,50MB/s 带宽时为 900 秒等)。
- 结果表明分配给内部操作的带宽越高,系统能够延迟 lantency spike 发生的时间越长。即本质只是延迟了 latency spike
- 然而,限制内部操作的带宽会减慢它们的速度。因此,这种方法增加了一种可能性,即在以后的某个时间点,许多 Compaction 同时运行,争夺有限的 I/O 带宽。
RocksDB with increased Cm
- 对比对象:增大内存组件的大小来看内存 buffer 大小是否会影响 RocksDB 延迟。
- 增大内存组件可使用的内存为 1GB,首先分为 2 个 500MB,然后分为 10 个 100MB。我们还改变了最大的 flush 次数,用一个和十个并行的 flush 线程进行试验。
- 我们发现使用 10 个内存组件和 1 个 flush 线程在推迟 latency spike 方面是最有效的,因为内存吸收了更多的写操作,而且从内存到 L0 的数据流和 L0 到 L1 的数据流是比较相近的。
- 然而,在所有这些情况中,我们迟早都会遇到尾部延迟峰值,原因与上面场景中的原因类似
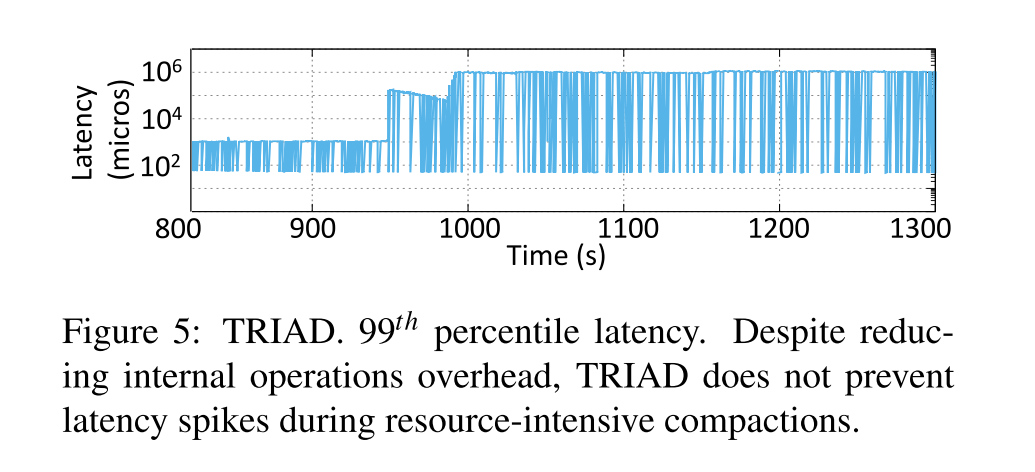
TRAID
- 减少内部操作的开销是不足以减小资源争用的。使用 TRAID 作为代表测试,99th 尾延迟结果如下所示。
- TRIAD 主要通过键重叠程度来决定何时执行 L0->L1 的 compaction,推迟较低层级(离内存组件更近)的 Compactions 将会导致更高层次的 compaction 被推迟,所以长远来看 TRIAD 增加了并发 Compaction 执行的可能性。因此客户端操作的 99th延迟 在1000s 之前几乎没有发生 spike,在那之后频繁发生。
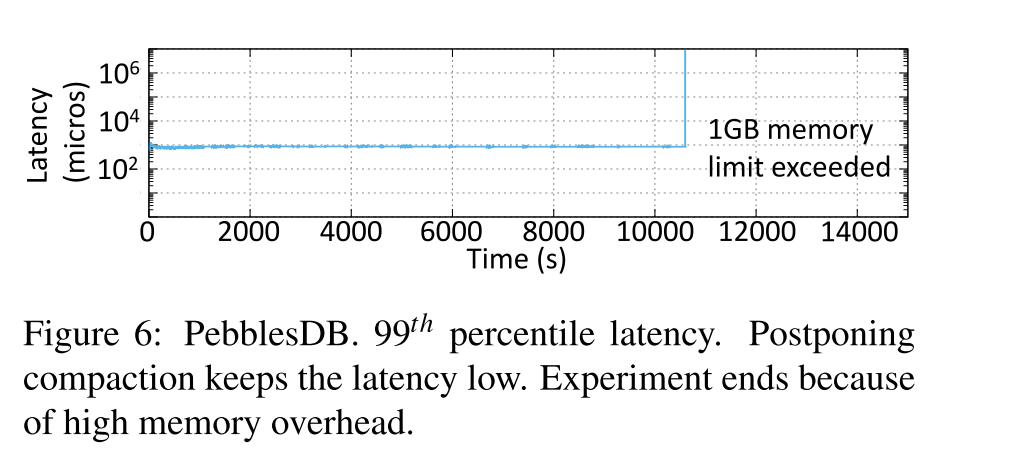
PebblesDB
- 下图展示了 PebblesDB 的情况,实验在 10500s 之后结束,尽管给了 PebblesDB 更多内存,还是会把分配的内存给耗尽。内存的消耗主要是因为在写敏感的负载中频繁地创建 guards 以及 bloomfilter。在正常运行期间,由于没有合并,Pebbledb 提供了非常好的尾部延迟。换句话说,LSM 树通过使用 guards 重新构建,但没有发生数据合并。
- 为了创建一个 PebblesDB 经历合并的情况,我们在一个读密集型工作负载(95:5)下运行它,这减少了内存压力。在这种工作负载下,尾部延迟在早期仍然很好,但是在大约 8 小时后,当合并开始时,系统实际上会停止运行。
- 当 PebblesDB 必须在树的最高层次上执行非常需要资源的 Compaction 时,它会暂停客户端操作。当这样的合并发生时,所有用于内部操作的线程都是繁忙的,因此它们不能从树的较低层次下推 guard 和键。因此,为了维护树的完整性,PebblesDB 会暂停客户端操作,直到合并结束。
异构工作负载与队头阻塞
- 我们表明,尾部延迟峰值的主要驱动因素之一是日志结构合并(LSM)键值存储维护操作与客户端工作之间的负面干扰。尾部延迟的另一个重要原因是工作负载的异构性,尽管在当前系统中更难展示这一点。在最先进的 LSM 键值存储中,工作负载异构性导致的延迟被客户端请求与 LSM 内部工作之间的干扰所掩盖。
- 揭示 LSM 键值存储中的队头阻塞现象。为揭示异构工作负载下的队头阻塞情况,我们在实验过程中禁用 LSM 的内部操作。这样一来,就不存在因刷新和合并操作而产生的干扰。我们按照 4.1 节所述,在预先填充数据的数据库上进行实验。此工作负载的读写比例与 YCSB A 工作负载相同(读占50%,写占50%),但数据项大小分布并不固定。键值对(KV)数据项大小分布与文献[23]和[4]类似:40% 为 1字节 - 15字节 的小数据项,59.9% 为 16 字节 - 1500 字节的中等数据项,0.1% 为 1501 字节 - 1兆字节 的大数据项。
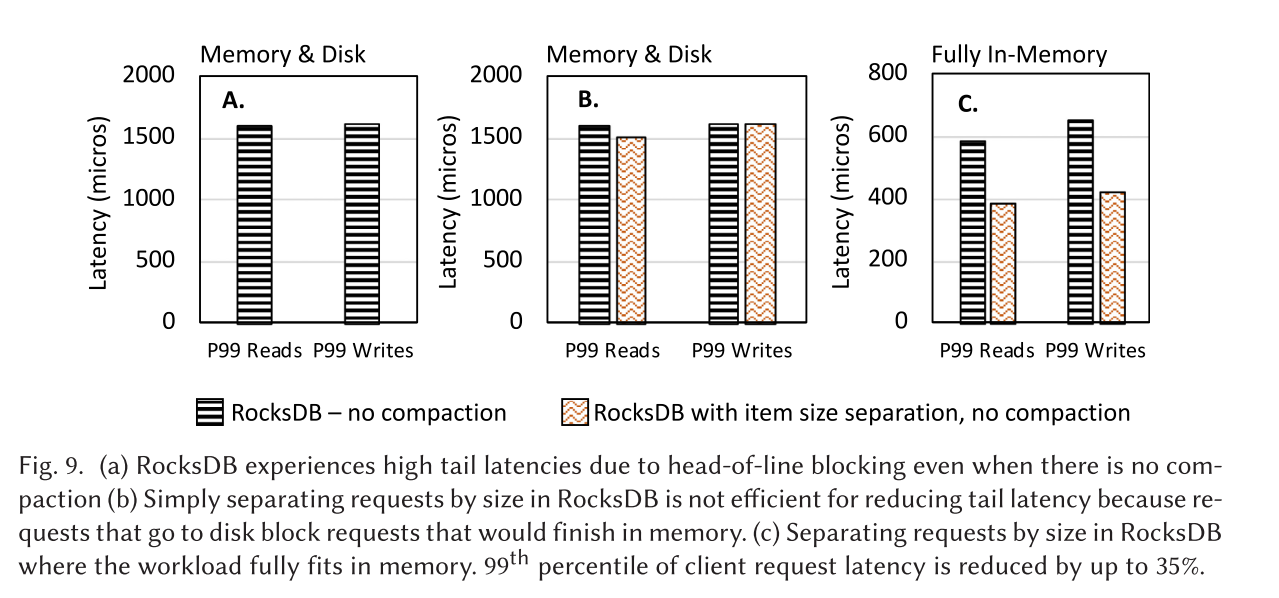
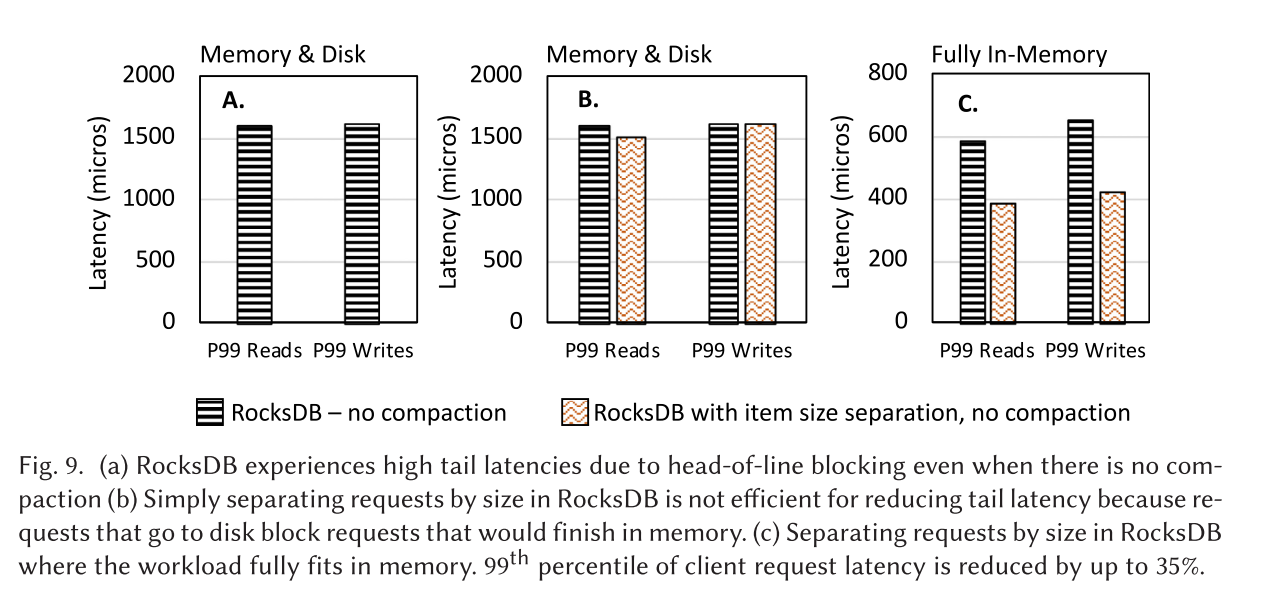
- 图 9A 展示了在 RocksDB 中禁用合并工作时,读写操作延迟的第 99 百分位数。即便没有合并干扰,且超过 99% 的操作涉及小数据项(即预期服务时间为几微秒),第 99 百分位数延迟仍增加了三个数量级,高达 1600 微秒。高尾部延迟的出现是由于队头阻塞。

- 针对队头阻塞的现有策略。此前的研究并未涉及 LSM 键值存储中的队头阻塞问题,因为该问题被其他延迟因素所掩盖。不过,此前的研究已经探讨了更广泛的队头阻塞问题。总体而言,有两种策略可用于缓解队头阻塞:
- (1)抢占操作。如果操作抢占是可行的,那么客户端请求会被分配到工作线程队列,以使每个队列的请求处理时间方差最大化[20]。操作抢占基于这样一个已知事实:最短剩余处理时间(SRPT)抢占策略能使平均完成时间最小化,对于具有重尾特性(方差较大)的请求处理时间分布尤其有效[8]。这类策略在数据中心作业调度场景中颇为成功[20]。数据中心作业与 LSM 键值存储操作之间的一个关键区别在于操作所需时间。在数据中心,作业运行时间可能是几秒,甚至几小时,而在键值存储中,大多数操作预计在几微秒到几秒内完成。这些严格的时间限制使得抢占逻辑带来的开销成本过高,因为如果没有硬件和操作系统的特殊支持,大多数操作无法被抢占[37]。
- (2)操作分组。如果无法进行抢占,那么请求会被分到不同队列,使每个队列中请求处理时间的方差最小化[19, 21]。操作分组基于波拉切克 - 欣钦公式,该公式表明,在一般条件下,请求完成时间与请求处理时间的方差成正比[39]。基于这一认识,人们开发了几种大小区间任务分配(SITA)调度策略[33],根据请求的预估处理时间将其分到不同队列。这种方法在内存键值存储(in - memory KVs)中得到了成功应用[23, 54]。一种常用的预估处理时间的策略是将处理时间与数据项大小(即需要读写的数据量)关联起来。然而,如果还涉及磁盘访问(大多数LSM键值存储工作负载都存在这种情况),该策略就不太奏效。
- 现有策略不适用于 LSM 键值存储。为了证明适用于内存键值存储的现有方法并不适用于持久化键值存储,我们在 RocksDB 上进行了两项实验,一项实验的工作负载可完全在内存中处理,另一项实验的工作负载则需要访问磁盘。在内存场景下,我们能够重现已有的实验结果:由于所有数据都从内存提供,请求大小能够很好地预估请求处理时间。然而,在磁盘场景中,仅依据请求大小并不能很好地衡量请求成本。请求可能需要访问磁盘,而这比仅从内存处理请求的成本要高得多。
- 图 9B 展示了 RocksDB 以及按请求大小进行区分的 RocksDB 的读写请求延迟的第 99 百分位数。两种情况均禁用了合并操作。在 LSM 键值存储中,按大小区分请求并无差别,因为读写请求的访问模式不同。写入操作在内存中完成,而部分读取操作则需要访问磁盘。相比之下,如果整个工作负载都能在内存中处理,这种策略最多可将尾部延迟降低 35%,因为数据访问路径不再影响延迟(图9C)。
Lessons learned
- 大概 4 个 lessons
- 尾延迟的主要原因是因为内存组件被写满而阻塞了写操作
- 根本原因有二:
- 磁盘组件 L0 层满了,导致 flush 操作挂起,而 L0 满是因为 L0->L1 的 Compaction 速度没有跟上
- 恰好大量合并线程在执行,因为有限的可用带宽的原因导致 flushing 很慢
- 简单地限制内部操作带宽不会解决 flush 时可用资源有限的问题,反而可能会加剧该现象
- 这个方法本质是推迟了后台 compaction 操作的进行,但长远来看增加了之后多个合并操作同时进行的可能性
- Chen Luo 等人关于 Compaction 的稳定性的研究也表明了 尽可能快地处理写操作可以最小化每次写操作的延迟。
- VLDB’19 On Performance Stability in LSM-based Storage Systems
- 现有的提高吞吐量的方法也只是延迟了 latency spike,长远来看还是加剧了该问题
- 最近的方法来提高吞吐量, 如选择性开始 compaction 或只执行最高 level 的 compaction, 避免延迟 spike 在短期内发生,但从长远来看还是加剧了该问题,因为他们也增加了之后许多 Compaction 并发执行的可能性
- 现有的在异构工作负载下改善尾部延迟的方法,在日志结构合并(LSM)键值存储领域并不奏效。
总结
- 从 Lesson 1 可以推断出,不是所有的内部操作都是平等的。在比较低的层次执行内部操作是很 critical 的,因为离内存组件比较近,如果不能很快地完成的话或者定时完成的话,会导致客户端操作陷入停顿
- 最后,作为经验教训 2 和 3 的推论,长时间持续进行性能测试至关重要,以免这些问题未被察觉。即便树状结构较低层级的内部操作很关键,但高层级的大型合并操作也不能太过滞后,这一点同样重要。推迟或过度有选择性地进行高层级合并操作并非可持续的策略。
SILK+
SILK+ design principles
- SILK+ 将我们从实验研究中汲取的经验教训整合到一个用于内部和外部工作的 I/O 调度器中。I/O 调度器的实际设计并非易事,因为它需要在一定程度上满足以下相互冲突的目标:
- (1)对于从磁盘提供服务的客户端读取请求,需要有足够的带宽。
- (2)在活跃的 填满之前,需要刷新不可变的 。
- (3) 中应始终有足够空间用于刷新操作。
- (4)高层级的合并操作绝不能妨碍其他活动。
- (5)此外,高层级的合并操作也不应过于滞后。
- (6)为客户端请求提供服务的磁盘访问操作,不应阻塞那些可在内存中完成的其他客户端请求。
- 所有这些目标都需要在用户负载不断变化的情况下实现。为了同时达成这些目标,SILK+ 遵循三条核心设计原则。
Opportunistically allocating I/O bandwidth to internal operations
- 基于一个如下所示的事实,生产环境中的负载通常是会随着时间变化的。
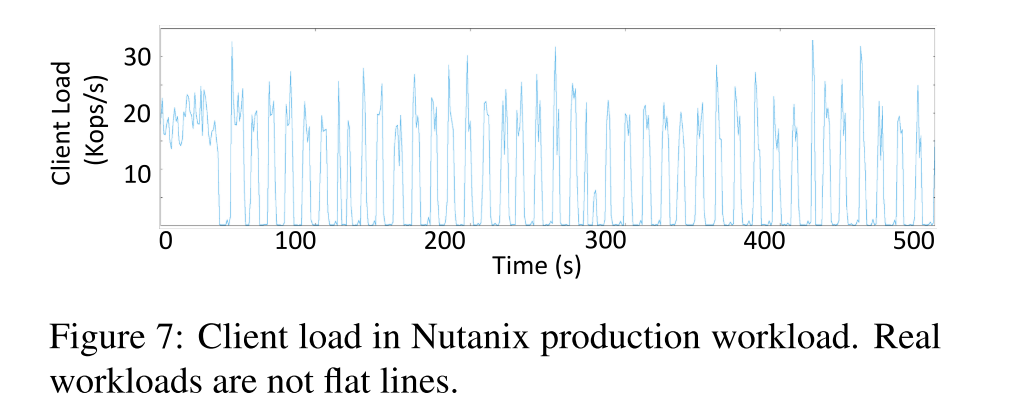
- 在客户机负载峰值期间,SILK 为更高级别的压缩分配更少的 I/O 带宽,并利用短暂的低负载时期来促进内部操作的处理。
- 动态 I/O 调节让 SILK 可以
- 限制客户端操作和内部操作之间的影响
- 避免长期积累过多的内部工作,防止长期超负荷的情况
- 低负载期间,大部分带宽分配给客户端请求【目标 1】。预留一些带宽用于关键的内部操作【部分解决目标 2 和 3】。
- 客户端负载较低的时候,为内部操作分配更多的带宽,SILK+ 确保高级别的 Compaction 不会落后太多【目标 5】
Prioritizing internal operations at the lower levels of the tree
- 目标 2,3,4
- 通过从 Lesson1 中学到的经验,给 flush 操作以及 L0->L1 的合并操作引入优先执行的策略。
- SILK 将内部操作分成了三种类型,根据其对客户端操作延迟可能带来的影响进行分类:
- Flush 需要足够快,从而让内存及时被释放以吸收前端写,这是直接影响写延迟的操作
- L0->L1 的合并操作 第二优先级,确保 L0 不会到达其容量限制,所以 flush 操作才能够顺利完成
- 是否可以考虑修改 L0 合并触发的条件来缓解该问题?
- L1 及其以下的合并操作为最低优先级,因为这些操作主要是为了维持 LSM 的树形结构,在短期内不会对延迟造成显著影响。
Client request separation
- 客户端请求分离。这一设计原则旨在实现目标(6),其优势在异构工作负载中最为显著。
- SILK+ 实施了一种新的客户端请求分离机制,该机制根据预估的处理时间将请求放入不同的工作线程队列。SILK+ 采用了一种新颖的技术来预估请求的处理时间。SILK+ 的技术与现有方法不同,它既考虑请求的大小(即请求写入或读取的字节数),也考虑数据访问模式(即请求是从内存还是磁盘获取服务)。
SILK+ implementation
- 算法 1 和算法 2 以伪代码形式给出了 SILK+ 调度器的高层概述。算法 1 展示了内部操作的调度策略。算法 2 展示了 SILK+ 用于客户端请求分离和负载均衡的策略。在 SILK+ 中,这些组件各自并行工作。
Opportunistically allocating I/O bandwidth
- 使用单独的线程来监控客户端的负载情况并限制内部操作的带宽。
- 监控的粒度 SILK_SLEEP_TIME 是可配置的,取决于负载的波动频率,在 SILK 中被配置为 10ms
- 假设 LSM KV 总可用 I/O 带宽为 T B/s,客户端请求经过监控发现使用了 C B/s,那么可分配给内部操作的带宽为 B/s,其中 ε 是一个小 buffer。
- 为了调整 I/O 带宽,SILK使用了一个标准速率限制器。SILK 维护一个最小可配置的 I/O 带宽阈值以供 flush 以及 L0->L1 的 compaction,因为这些操作直接影响延迟,所以还是需要保证一直可以执行。设定了一个下界。
- 为了最小化与更改速率限制相关的开销,只有当当前值与新测量值之间的差异很大时,SILK 才会调整限制。作者设置了经验值阈值为 10MB/s,发现更低的阈值或造成频繁的 rate limit 的变化,ε 是为了吸收客户端负载的小波动,这些小波动没什么必要通过速率限制器来调整内部的操作带宽。
Prioritizing and preempting internal operations
- 回想一下,在 LSM 键值存储中,内部工作由一组内部工作线程处理。一旦一次刷新或压缩操作完成,系统会通过评估各层级的大小以及内存组件的状态,来检查是否还需要更多内部工作。如果有需要,更多内部工作任务会被调度到一个内部工作队列中。
- SILK+ 维护三个内部工作线程池:一个用于刷新操作的高优先级线程池,一个用于从 L0 到 L1 合并操作的中优先级线程池,以及一个用于更高级别合并操作的低优先级线程池(算法 1,第 1 - 3 行)。带宽通过令牌进行控制,令牌由一个 I/O 带宽速率限制器跟踪记录 [30]。
- Flushing
- 在内部操作中,刷新操作具有最高优先级。刷新操作拥有专用线程池,并且总能获取到可供内部操作使用的 I/O 带宽。最小刷新带宽的设定要足以确保在活跃内存组件填满之前,将不可变内存组件刷新完毕。
- SILK + 目前的实现方案允许有两个内存组件(即一个不可变组件和一个活跃组件)以及一个刷新线程。如果内存条件允许,设置多个内存组件和刷新线程或许有助于应对更长时间的客户端活动高峰。
- L0 to L1 compaction
- SILK 需要 L0 到 L1 的 compaction,以确保 L0 上有足够的 flush 空间。有一个专门的中优先级线程池。当调度器分配 I/O 带宽时,从 L0 到 L1 的合并操作优先于更高级别的压缩操作(算法 1,第 21 - 29 行)。
- 从 L0 到 L1 的合并操作,和所有内部操作一样,要接受动态 I/O 流量限制。不过,此类合并操作从不暂停,即便在 SILK+ 为优先处理用户请求而大幅限制内部操作 I/O 带宽的情况下,也会以最低限度的带宽运行。在这种情况下,上述最小带宽由刷新线程和从 L0 到 L1 的合并线程共享。由于键范围重叠会引发一致性问题,每次最多只能运行一个从 L0 到 L1 的合并操作。在内部工作 I/O 带宽极度受限期间,最小带宽会在刷新线程和从 L0 到 L1 的合并线程之间平均分配。RocksDB 的最新版本支持从 L0 到 L0 的合并操作,作为一种快速减少 L0 上 SSTable 数量的优化手段[29]。由于这种优化有助于推进刷新操作,SILK+ 将这种情况与从 L0 到 L1 的压缩操作同等对待。
- Higher-level compactions
- 更高级别压缩操作。高于 L1 层级的合并操作安排在低优先级压缩线程池中。正如5.2.1节所描述的动态速率限制器所示,它们利用可用的I/O带宽。由于用户负载过高,SILK+可以在线程池层面暂停和恢复这些较大规模的合并操作。
- 与当前大多数 LSM 键值存储一样,SILK+ 支持并行合并。默认情况下,假设各压缩线程的执行力度相同,每个线程会获得相似的资源份额。LSM 键值存储不允许从 L0-L1 的并行合并,所以,如果允许大量并行合并,大多数合并线程会在更高级别上工作。这对客户端操作延迟不利,因为从 L0 到 L1 的合并对系统性能至关重要,若能获得大部分资源会更有益。减少线程池规模,再结合 SILK+ 的合并抢占机制,可让每个内部工作线程获得更大份额的资源,从而更快完成关键的合并操作。
Client request separation.
- SILK + 的客户端请求分离策略基于以下原则:
- (P1)在对客户端请求进行分离时,同时考虑请求大小和数据访问路径;
- (P2)为降低延迟,不应让大请求长期等待或被丢弃;
- (P3)持续让所有工作线程保持忙碌,比实现完美的负载均衡更为重要。负载均衡策略如算法 2 所示。
- SILK+ 定义了以下几类请求:
- (1)小内存请求(即可以在内存组件中完成的写入和读取操作;算法 2 中的 SHORT_WRITE 和 SHORT_READ);
- (2)大内存请求(即可以在内存组件中完成的写入和读取操作;算法 2 中的 LONG_WRITE 和 LONG_READ);
- (3)持久存储请求(即从磁盘组件提供服务的读取和扫描操作;算法 2 中的 DISK_READ)。
- 这种划分是基于对我们典型工作负载的分析。不过,如有必要,该方法可以推广,纳入不同或更细粒度的划分。例如,SILK+ 可以使用诸如[23]和[60]中更自动化的方法来确定划分方式。
- 每个工作线程都有自己的请求队列,专门处理一种类型的请求(例如,只处理短写入请求)。这种方法的一个优点是工作线程之间无需同步。然而,可能会出现资源利用不足的问题:根据工作负载的不同,一些工作线程可能处于空闲状态,这与原则 3 相矛盾。为避免这个问题,SILK+ 使用了一个负载均衡器,它
- (1)实现将用户请求分配到队列的逻辑,
- (2)负责确保所有工作线程都处于忙碌状态。
- 工作线程只需处理其队列中的下一个请求(算法 2,第37 - 42行)。负载均衡器为每个工作线程静态分配一个类别亲和性。假设有一个类别为 c 的用户请求 R 到达准入控制器。R 的处理方式如下:
- (1) 首选队列。如果存在一个对类别 c 具有亲和性的空队列 Q,那么请求 R 将被添加到 Q 中(算法2,第15 - 21行)。
- (2) 所有队列已满。如果所有队列(包括对类别 c 没有亲和性的队列)都至少已入队一个请求,那么请求 R 将被放入对类别 c 具有亲和性且请求数量最少的队列中(算法2,第33 - 35行)。
- (3) 任务窃取。如果所有对类别 c 具有亲和性的队列都不为空,但存在另一个空队列 Q',且 Q' 对处理时间比 c 所属操作类别更耗时的操作类别具有亲和性,那么请求 R 将被发送到 Q'。否则,我们按情况 2 进行处理(算法2,第25 - 31行)。
- 任务窃取算法确保工作线程每次只能窃取一个请求,因为只有工作线程的队列为空时才会发生任务窃取。因此,工作线程队列中不会积累无亲和性的请求。该算法还确保,亲和类别中的请求不会在无亲和性的请求之后等待超过一次操作的时间。最后,如果一个有亲和性的请求 在一个无亲和性的请求 之后等待,那么 的处理时长总是比 短。例如,对短写入操作有亲和性的工作线程,不可能窃取长扫描请求。
- 队列分配策略。对于读请求,负载均衡器事先并不知道读取的键值对(KV)项的大小。为了对读请求进行分类,负载均衡器乐观地假设所有读请求都是短内存读请求(算法2,第6 - 11行)。当处理读请求时,键值存储会检查该键值对项是否存在于内存中。如果存在且值的大小较小,那么请求就完成了。如果不存在,请求会返回给负载均衡器,并指明键值对项是在内存中未找到(即该请求需要访问磁盘),还是在内存中找到了但值很大。然后,负载均衡器会将读请求重新调度到合适的队列。对于写请求,负载均衡器可以直接将它们分配到正确的队列,因为请求到达时更新数据的大小是已知的。
Evaluation
Setup
- RocksDB-SILK, TRIAD-SILK, RocksDB, TRIAD, RocksDB that uses the auto-tuned rate limiter
- focusing on write-intensive workloads
- db_bench
- Measurements:
- 负载生成器线程根据工作负载特征在开放循环中发出请求。它们将请求保存在KV存储工作线程的队列中
- 延迟是在loadgenerator线程侧测量的,它同时捕捉队列时间和处理时间
- 测量第99百分位的尾部延迟和一秒间隔内的吞吐量(即,不是整个实验运行的累积)。
- Dataset:
- 生产和合成工作负载的数据集大小都大约为500GB。kv元组的尺寸在生产和合成工作量之间有所不同
- Config:
- 128MB memory component size and two memory components
- flushing and L0 to L1 compactions proceed at a rate of 50MB/s if SILK paused the other internal operations
- The total I/O bandwidth allocated to the LSM KV store is 200MB/s.
level0-slowdownlevel0-stopare configured to very large values in all data stores so as not to artificially interfere with the measured latency- thread pool of 4 threads for internal operations (including the flushing thread)
- All systems are pinned to 16 cores, out of which 8 are used by the worker threads, and 8 are used by the internal operations and other LSM threads (e.g., monitoring the client load in SILK)
- The load-generator threads run on separate dedicated cores.
- Note: Compression and commit logging are disabled
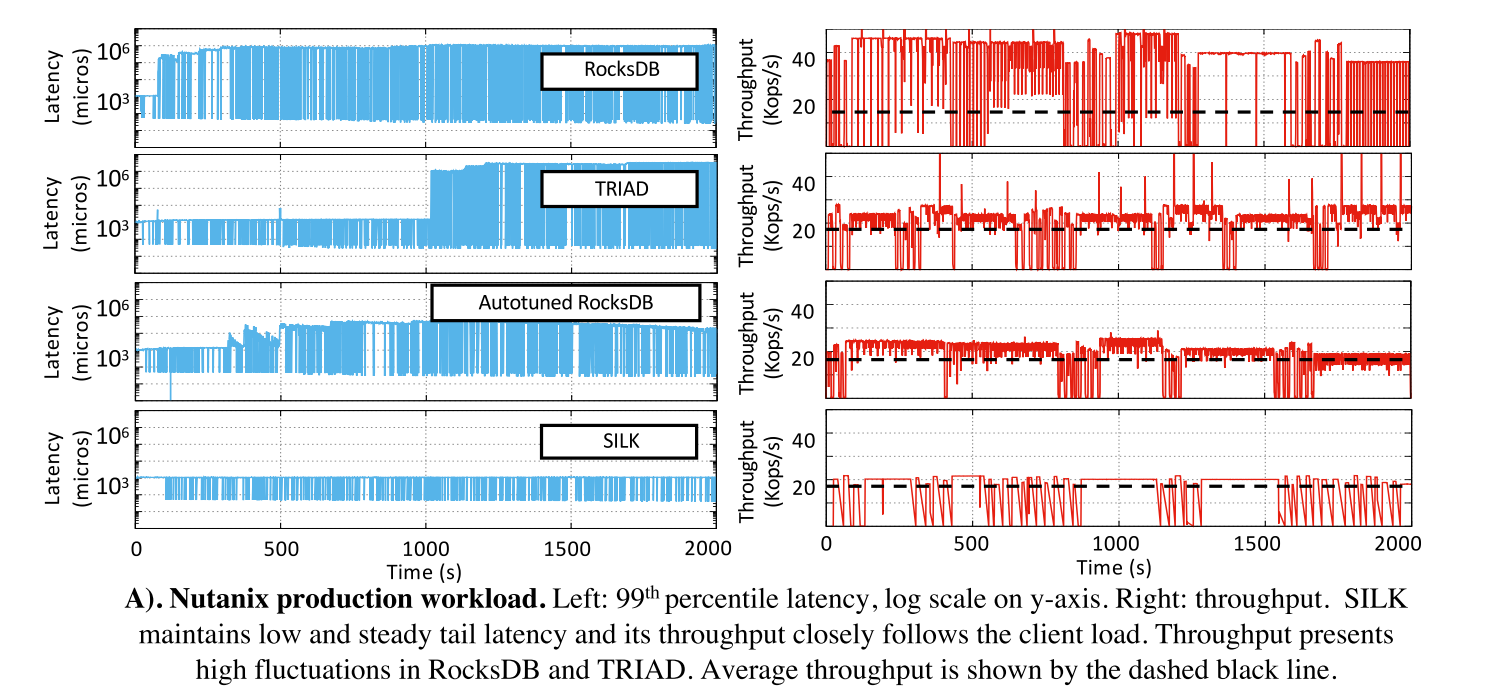
Nutanix workload
- 57:41:2 write:read:scan
- 客户端请求以突发的方式到达(峰值约为20K请求/s),由低活动周期(山谷约为数百请求/s或更少)分隔。山谷的典型持续时间在5到20秒之间,平均山谷长度约为15秒。大多数峰值(大约90%)是10 - 20秒之间的短脉冲。较长的峰值(>100)构成了工作负载的其余部分。最大峰值持续约400秒。
- 延迟下降明显,相比于 RocksDB TRAID 下降了三个数量级,相比于 AUTO-TUNED RocksDB 下降了2个数量级。当有更多的内部工作要做时,自动调优器只会增加I/O带宽,而且它与用户负载无关。
- SILK中的吞吐量接近所提供的客户机负载,而RocksDB中的吞吐量波动较大。由于内部操作的干扰,客户端操作在工作线程队列中构建。当它们能够继续运行时,它们会被快速处理,从而导致吞吐量峰值。TRIAD和自动调优的RocksDB与所提供的客户机负载更接近,但吞吐量仍然存在波动,这与尾部延迟的增加有关。
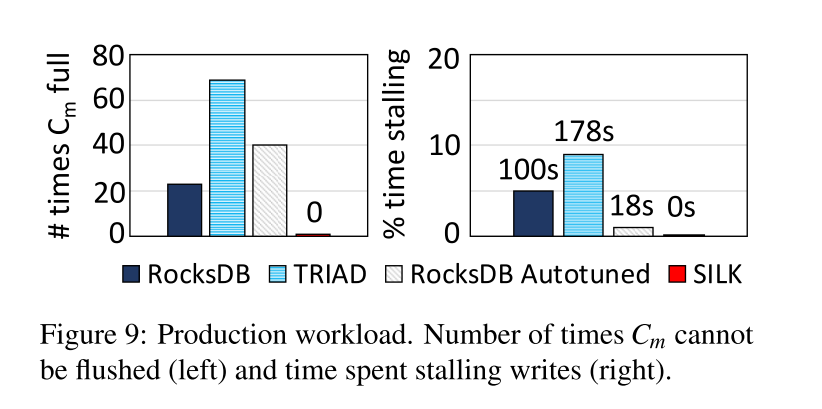
- 显示了 Cm 不能立即刷新的次数(左图),以及与实验持续时间相关的写入停滞时间(右图)。TRAID 因为 L0->L1 压缩策略的关系延迟 flush 的问题最严重。
- 展示了rocksdb - silk在生产工作负载24小时运行时的第99百分位延迟和吞吐量时间序列。
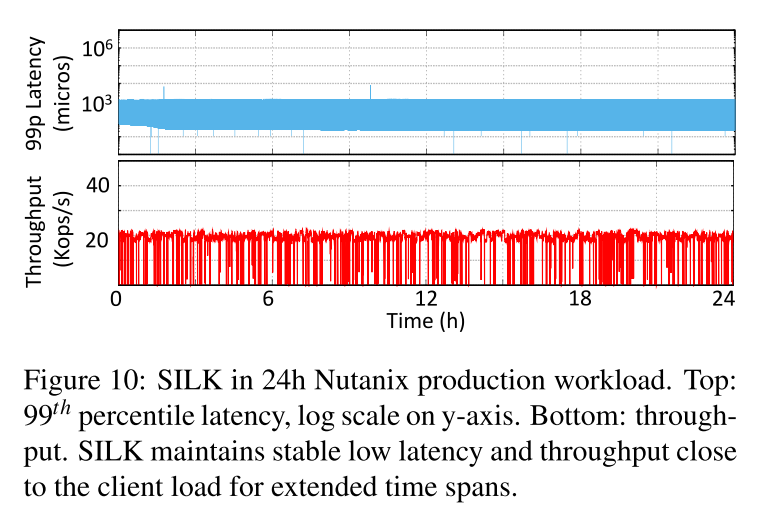
- 显示了在生产工作负载的200秒内,在RocksDB-SILK中的I/O带宽分配的详细信息。内部的工作可能会暂时推迟,但最终是要长期完成的。RocksDB-SILK在24小时内压缩了大约3TB的数据,而且等待调度的压缩操作从不超过3个。工作线程没有写停顿,整个实验中排队的操作少于3个。

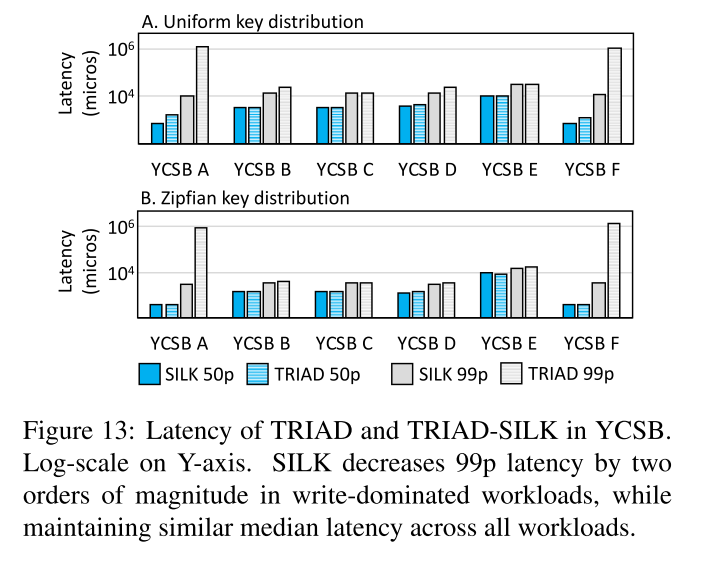
YCSB benchmarks
- SILK 对于不同分布的负载影响不大。uniform 分布下,SILK 在写密集的负载下开销最大,因为需要频繁地压缩、调度。读的话和 TRAID 差距不大,因为 L0 中每个 file 都有 Bloomfilter,在 L0 中第一次找到以后就返回了不需要见所有的 L0 的文件(注意需要按照时间先后顺序或版本信息来检索)。所以大部分时间只有 L0 中的一个文件被读取,但是 SILK 延缓了 L0->L1 的压缩会导致一定程度上对读性能的影响。
- zipfan 分布下大多数请求在内存中就处理了,因此 compaction 也比较少,因此 SILK 带来的吞吐量影响也就比较少。
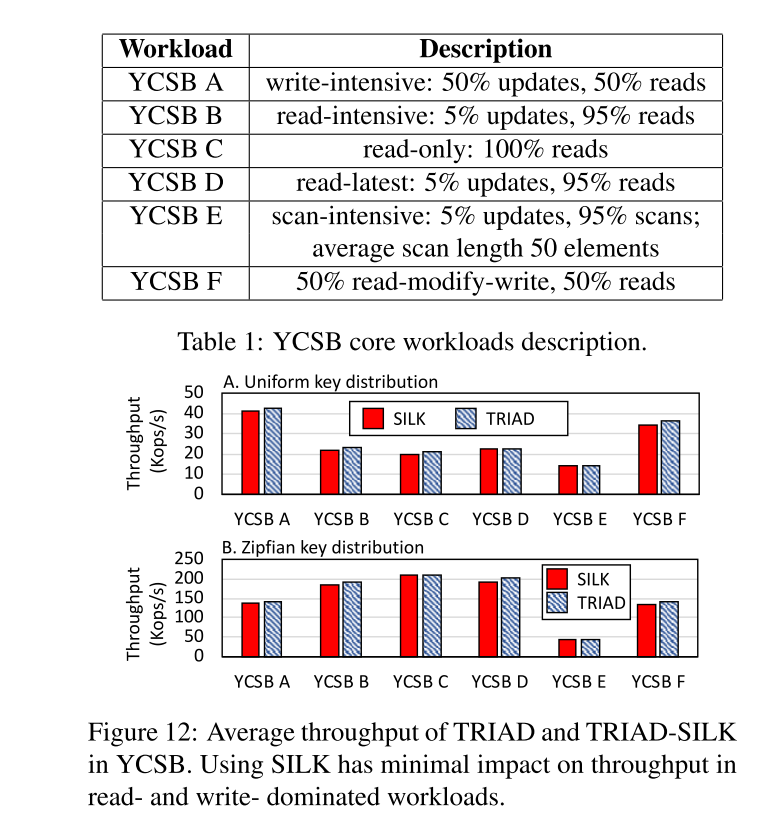
- 尾延迟下降就比较明显了
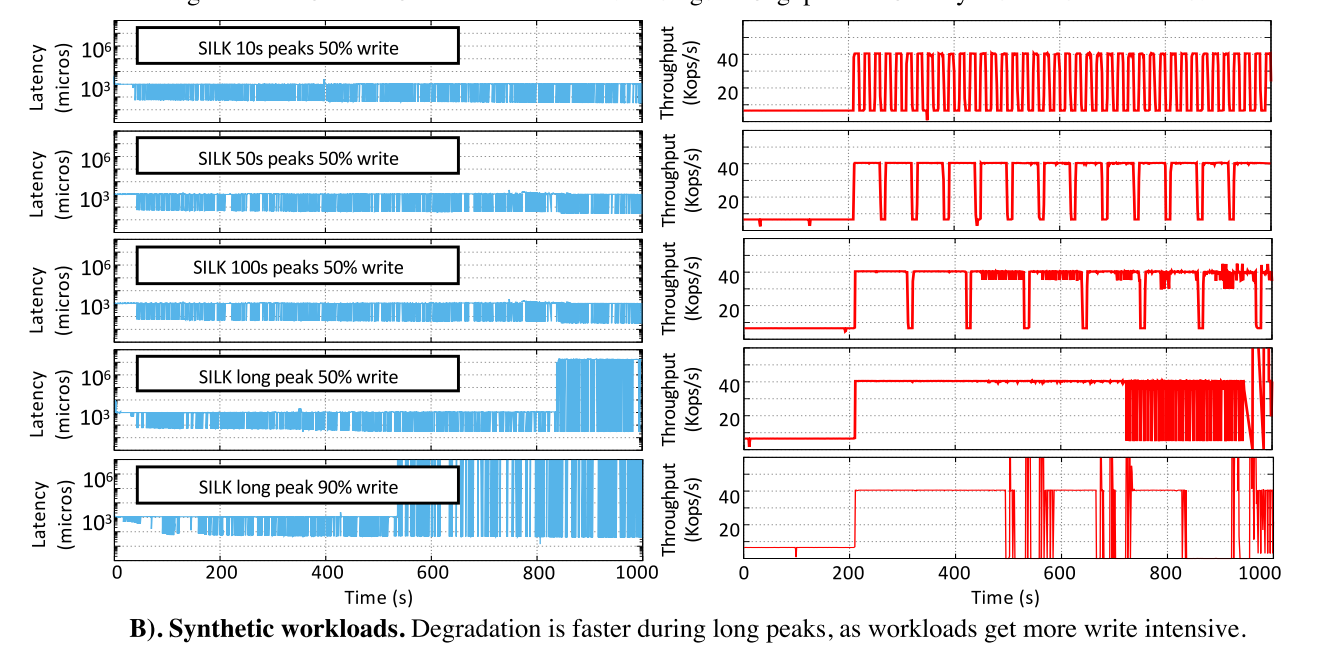
Stress testing for long peaks
Workload description.
- 主要基于 YCSB-A,读写50:50,其中,我们改变客户端负载峰值和谷值之间的比例(逐渐增加峰值持续时间,同时保持谷值持续时间不变)。8B key, 1024B value, uniform key distribution。低活动期间的客户端负载大约是10K operations/s,高峰期间大约是 40K operations/s。为了给系统施加压力,所提供的峰值和低谷负载都比我们的生产工作负载要高。
Results
- 前三行显示了一个50:50的写:读工作负载,其中峰值:山谷长度的比例是不同的:峰值持续10秒、50秒和100秒,而山谷持续10秒。SILK可以轻松地在客户机负载中维持这些峰值和低谷,从而保持低延迟和稳定的吞吐量。
- 在图的最后两行,我们展示了一个长峰值的实验结果,看看SILK的性能在什么时候开始下降。
- 第四行显示50:50写:读工作负载的结果,最后一行显示90:10写:读工作负载的结果。
- 尽管有关键内部工作的优先级,但如果峰值负载高且峰值持续时间长,系统无法为内部工作分配足够的资源,性能最终会开始下降。此外,正如预期的那样,写操作的比例影响峰值可维持的时间。对于90%的写工作负载,SILK的性能在大约500秒(峰值时为300秒)时开始下降,而对于50%的写工作负载,峰值可以维持到大约700秒(峰值时为500秒)。尽管表现出性能下降,SILK仍然能够处理代表真实应用程序的具有挑战性的工作负载。我们的生产工作负载最多有400个峰值,50%的写和负载峰值只达到合成工作负载峰值的一半
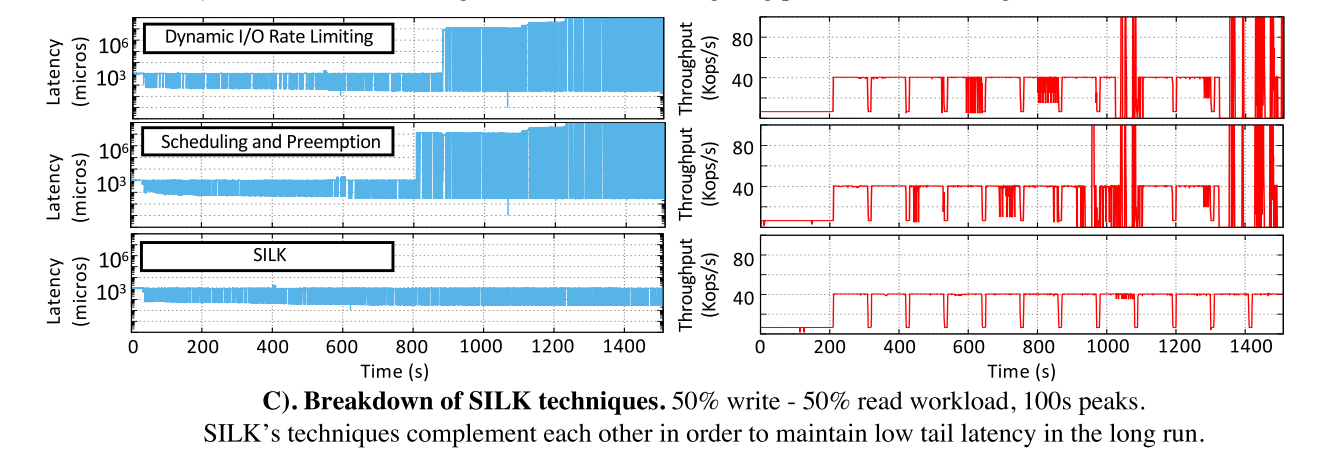
Breakdown
- 如下展示了 SILK 各种变体的性能表现。一行显示了一个版本,其中我们启用了SILK的动态I/O带宽速率限制,但禁用了优先级和抢占。第二行显示的是互补版本,它使用优先级和抢占,但I/O带宽不受控制。最后一排是 SILK。单独而言,这两种技术都不能维持客户机负载。
- 通过动态带宽分配,减少了内部和外部的工作干扰,然而,随着实验的进行和需要进行更大的 compaction,紧急的内部操作减慢了
- 良好的优先级将树结构保持在接近内存组件的级别上,允许刷新和L0 - L1压缩在不降低速度的情况下进行。然而,当需要进行更大的 compaction 时,带宽不受控制这一事实会导致内部和外部工作之间的负干扰
SILK+
Abstract
- 期刊 TOCS20 上发表的 extend 文章,相比于 SILK 多了一个点:separating client requests by size and by data access path。根据估计的请求处理时间以及数据访问路径来分离客户端请求。
Introduction
- 尾延迟的另外一个重要原因是:从操作组合和 item 大小来看,工作负载的异构性,几个计算量更大的请求会降低大部分较小请求的速度。即负载的一些内在特性。
- 针对较大的 KV 项或跨越多个KV项的请求(例如,范围扫描)会延迟较小的延迟敏感请求。由于 LSM KVs 的线程体系结构以及客户端操作类型之间缺乏区分,导致了这种队头阻塞。YCSB 中没有设计这种 item 大小变化的情况,固定了项的大小。就其实大量的生产环境中的负载的 KV 项大小都是会变化的,不是一成不变的。
- 在内存数据存储的背景下,研究了 head-of-line 阻塞的问题。相反,在持久的 KV 存储情况下,它得到的关注较少。原因是,在传统的 LSM KVs 中,工作负载不均的影响被内部操作的干扰所抵消。一旦内部操作干扰的问题被缓解,负载异构的问题就还是会显现出来。

- 典型的 LSM KV 工作负载包含对不同 KV 项目大小的读、写和扫描的混合。下图展示了 Nutanix 生产环境中的工作负载的分布,在Facebook、维基百科、Flickr和Memcachier的生产工作负载中也报告了类似的条目大小变化。如上所述,最先进的LSM KVs在 first-come-first-served 的基础上为客户端操作提供服务,这会导致小型操作在更耗时的请求之后被阻塞。
初步实验证明问题
- 导致尾部延迟的另一个重要原因(尽管在当前系统中更难显示)是工作负载不均。在最先进的LSM kv中,由工作负载异构引起的延迟被客户机请求和内部LSM工作的干扰所掩盖。
Exposing head-of-line blocking in LSM KVs
- 为了暴露在异构工作负载下的队头阻塞,我们在实验期间禁用了LSM内部操作。因此将不会存在 flush 和 compaction 带来的干扰。
- 负载:YCSB-A(R:W=50:50),但是每一项的大小的分布是不固定的:40% small items of 1B–15B,59.9% medium items of 16B–1500B,0.1% large items of 1501B–1MB
- 下图 A 展示了 RocksDB 的读写操作延迟,即使没有压缩干扰,即使超过 99% 的操作都是小的(即,预期的服务时间是几微秒),第 99 个百分位延迟也会增加 3 个数量级,达到1600微秒。高尾延迟是由于队首阻塞而发生的
Existing strategies for head-of-line blocking
- 之前的研究中没有人研究过 Head-of-line blocking,因为这个问题被其他导致延迟的原因给掩盖了,然而,在之前的工作中已经解决了 head-of-line blocking 这个更大的问题。在较高的层次上,有两种策略可以用来缓解头部阻塞:
Preempting operations
- Preempting operations:如果操作抢占是可能的,那么客户端请求就被分配给工作线程队列,这样每个队列的请求处理时间的差异就会最大化,操作抢占是基于已知的事实,即最短剩余处理时间(SRPT)抢占策略可以最小化平均完成时间,对于具有重尾特性(具有高方差)的请求处理时间分布特别有效。这种策略在数据中心的作业调度环境中是成功的,数据中心作业和 LSM KV 操作之间的一个关键区别是操作所花费的时间。在数据中心,作业运行几秒钟,甚至几个小时,在 KVs 中,大多数操作预计在几微秒或几秒钟内完成。这些紧张的时间限制使得抢占逻辑所增加的开销在成本上难以承受,因为如果没有硬件和操作系统的特殊支持,抢占大多数操作是不可能的
Grouping operations
- Grouping operations:如果不可能抢占,则将请求分离到队列中,以便使每个队列的请求处理时间变化最小。操作分组基于Pollaczek-Khinchine公式,该公式指出,在一般情况下,请求完成时间与请求处理时间的方差成比例。在此基础上,已经开发了几种大小间隔任务分配(SITA)调度策略,根据估计的处理时间将请求分离到不同的队列中。这种方法在内存中的KVs中得到了成功的应用。估算处理时间的一个流行策略是将处理时间与项目大小(即需要读或写的数据量)关联起来。但是,如果也访问磁盘,这种策略就不会成功,这在大多数LSM KV工作负载中都是如此
Existing strategies not suitable for LSM KVs
- 为了证明现有的内存中KVs方法在持久化KVs中是无效的,我们在RocksDB上运行了一个实验,其中工作负载适合内存,工作负载需要访问磁盘。我们可以在内存设置中复制现有的结果——因为所有的服务都是从内存提供的,所以请求大小可以很好地估计请求处理时间。然而,在磁盘上,单凭请求的大小并不能很好地反映请求成本。请求可能需要访问磁盘,这比仅从内存提供请求要昂贵得多。
- 图9(b)显示了 RocksDB 和区分了请求大小的 RocksDB 的第99百分位数读写请求延迟。在这两种情况下都禁用了压缩。由于读写请求的访问模式不同,按大小分开请求在LSM KVs中没有区别。写在内存中完成,而一些读需要转到磁盘。相反,如果整个工作负载适合内存,此策略可以将尾部延迟减少35%,因为数据访问路径不再影响延迟(图9(c))
- 简而言之就是因为磁盘访问的开销导致现有的请求调度策略带来的收益并不明显
Lessons
- 多了一个 lesson: 现有的在异构工作负载情况下改善尾部延迟的方法在LSM KVs域中并不有效。
SILK+
Principles
- 主要多一条:为客户端请求服务的磁盘访问不应该阻塞其他可以在内存中完成的客户端请求。
- Client request separation:SILK+实现了一个新的客户端请求分离机制,该机制根据请求的估计处理时间将其放置到不同的工作线程队列中。SILK+实现了一种新的技术来估计处理请求的时间。SILK+的技术与现有的方法不同,它考虑了请求的大小(即请求写入或读取的字节数)和数据访问模式(即请求是从内存还是磁盘提供的)。
- 简而言之就是 SILK+ 设计了一种新的基于负载请求特性的且应用在 LSM KVs 的 IO 调度策略
Implementation
- 相比于 ATC19 多了一些伪代码
Opportunistically Allocating I/O Bandwidth
- SILK+ 持续监控客户端操作所使用的带宽,并将可用的剩余I/O带宽分配给内部操作(算法1,第6-18行)。客户机负载监视和速率限制由单独的 SILK+ thread处理。监视粒度(SILK_SLEEP_TIME)是一个系统参数,它取决于工作负载中的波动频率;SILK+中的监控粒度目前配置为10毫秒。
- 如果LSM KV存储可用的总I/O带宽是 T B/s,则SILK+测量带宽客户端请求使用的 C B/s 模式,它不断调整内部操作带宽到 I=T−C−ϵ B/s。为了调整 I/O 带宽,SILK+使用了一个标准速率限制器,它有一个基于令牌的实现 RocksDB Rate Limiter,SILK+维护了用于刷新和L0到L1压缩的最小可配置I/O带宽阈值,因为这些操作直接影响客户端延迟。

- 为了最小化与更改速率限制相关的开销,SILK+仅在当前值与新测量值之间的差异显著时才调整限制(算法1,第9行)。我们根据经验将这个阈值(BW_CHANGE_THRESHOLD)设置为10 MB/s。我们发现,较低的阈值会导致频率限制的过度频繁变化。ϵ 的作用是考虑到客户端负载的微小波动,这些波动不足以用速率限制器调整内部操作带宽。
Prioritizing Internal Operations
- 回想一下,在LSM KVs中,内部工作是由内部工作线程池处理的。一旦刷新或压缩完成,系统将通过评估级别的大小和内存组件的状态来检查是否需要更多的内部工作。如果需要,将在内部工作队列中调度更多的内部工作任务。SILK+维护三个内部工作线程池:一个高优先级的池用于刷新,一个中等优先级的池用于L0到L1压缩,以及一个低优先级的池用于更高级别的压缩(算法1,第1 - 3行)。带宽通过令牌控制,令牌通过I/O带宽速率限制器跟踪 RocksDB Rate Limiter
- Flushing: 最高优先级,刷新有它们专用的线程池,并且总是能够访问内部操作可用的I/O带宽。选择的最小刷新带宽足以在活动内存组件填满之前刷新不可变内存组件。SILK+的当前实现允许两个内存组件(即一个不可变组件和一个活动组件)和一个刷新线程。如果内存约束允许,使用多个内存组件和刷新线程可能有助于维持较长的客户端活动高峰。
- L0 to L1 compaction:
- SILK+ 需要L0到L1的压缩,以确保L0上有足够的 flush 空间。L0到L1压缩有一个专用的中等优先级线程池。当调度程序分配I/O带宽时,L0到L1压缩优先于更高级别的压缩(算法1,第21-29行)。
- 和所有内部操作一样,L0到L1压缩也需要动态I/O节流。然而,这种压缩从来不会暂停,即使在SILK+严重限制内部操作上的I/O带宽以对用户请求进行优先级排序的情况下,这种压缩也会以最小的带宽运行。在这种情况下,上面提到的最小带宽由刷新线程和 L0 to L1 compaction 共享。由于键范围重叠导致的一致性问题,最多一次只能运行一个L0到L1压缩。在内部工作I/O带宽的极端限制下,flush线程和L0到L1压缩线程平均共享最小带宽。RocksDB最近的版本支持L0到L0压缩,作为一种优化,可以快速减少L0上sstable的数量。由于这种优化有利于进行刷新,因此SILK+将这种情况视为L0到L1压缩。
- Higher-level compactions: 在低优先级压缩线程池中调度高于L1级别的压缩。它们利用可用的I/O带宽,SILK+可以在线程池级别暂停和恢复这些较大的压缩(因为用户负载很高)。
- ...
Client Request Separation
- SILK+的客户端请求分离策略依赖于以下原则:
- (P1) 在执行客户端请求分离时,同时考虑请求大小和数据访问路径;
- (P2) 大的请求不应该被饿死或删除以减少延迟;
- (P3) 保持所有工作线程都处于忙碌状态比实现完美的负载平衡更重要。
- SILK+定义了以下类型的请求: 拆分基于对典型工作负载的分析
- (1) 小的内存请求(例如,可以在内存组件中完成的写和读请求;SHORT_WRITE和SHORT_READ,如算法2所示);
- (2) 大的内存请求(例如,写和读可以在内存组件中完成;如算法2中的LONG_WRITE和LONG_READ);
- (3) 持久存储请求(即从磁盘组件读取和扫描,如算法2中的DISK_READ)。
- 但是,如果有必要,可以将此方法一般化,以包含不同的或更细粒度的分割。例如,SILK+可以使用更自动化的方法来确定分割。参考一些分类方式
- NSDI2019:Size-aware sharding for improving tail latencies in in-memory key-value stores
- TPDS05: Workload-aware load balancing for clustered web servers
- 每个工作线程都有自己的请求队列,专门化一种类型的请求(例如,只服务简短的写)。这种方法的一个优点是工作线程之间不需要同步。然而,可能会出现资源利用率不足的问题:根据工作负载,一些工作线程可能是空闲的,这与 P3 相矛盾。为了避免这种问题,SILK+使用负载平衡器,它
- (1) 实现将用户请求分配给队列的逻辑
- (2) 负责确保所有工作线程都处于繁忙状态。工作线程只需要服务其队列中的下一个请求(算法2,第37-42行)。负载平衡器静态地为每个工作线程分配一个类关联。假设一个类型为C的用户请求R到达控制器。R的处理方法如下:
- (1) Preferred queue 优先队列。如果有一个与类 C 有亲缘关系的空队列 Q,则将 R 添加到 Q 中(算法2,第15-21行)
- (2) All queues full 所有队列已满。如果所有队列(包括与类C没有关联的队列)至少有一个请求进入队列,则 R 进入与类 C 有关联的最空队列(算法2,第33-35行)。
- (3) Work stealing 工作窃取。如果所有与 classC 有关联的队列都不是空的,但是有另一个队列 Q' 是空的,并且与一个处理时间比 C 更昂贵的操作类有关联,那么R将发送到 Q'。否则,我们继续进行情况2(算法2,第25-31行)。
- 工作窃取算法确保工作线程一次只能窃取一个请求,因为它们的队列需要为空才能发生工作窃取。因此,工作线程队列中不会出现无关联的请求堆积。
- 该算法还确保关联类中的请求不会在关联类之外的请求之后等待多个操作。最后,如果一个具有亲和性的请求 R_A 在一个没有亲和性 的请求之后等待,那么 总是比 短。 例如,长时间扫描不可能被与短写有关联的工作线程窃取。

Queue assignment strategy
- 对于读请求,负载平衡器事先不知道读KV项的大小。为了对读请求进行分类,负载平衡器乐观地假设所有读都是内存中的短读(算法2,第6-11行)。当读取被处理时,KV存储检查KV项是否存在于内存中。如果是,并且值大小很小,则请求完成。如果没有,请求返回给负载均衡器,并指示是否在内存中没有找到KV项目(即请求需要转到磁盘),或者是否在内存中找到了KV项目,但这个值很大。然后,负载平衡器将读请求重新调度到适当的队列。对于写请求,负载均衡器很容易将它们分配到正确的队列,因为当请求到达时,更新大小是已知的。
Evaluation
- 多了一个测试
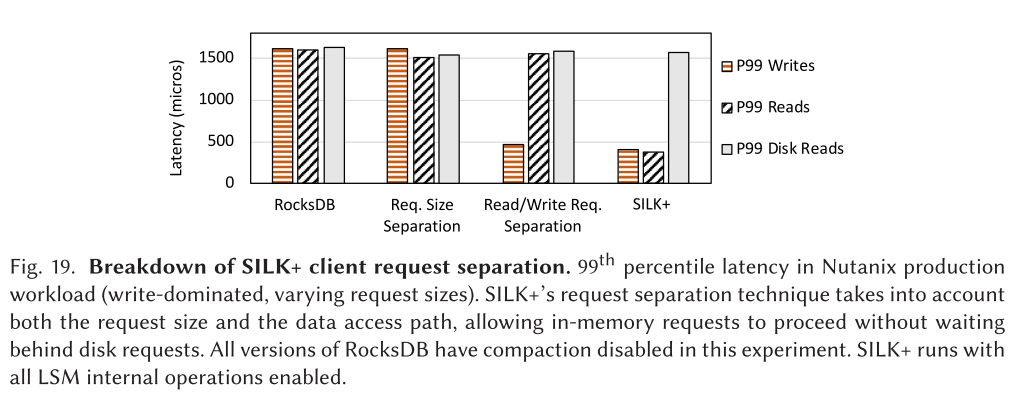
- 图19显示了Nutanix工作负载中SILK+的第99百分位延迟。我们比较SILK+有三个版本的RocksDB——原始的RocksDB、按大小分隔请求的RocksDB(与SILK+执行大小分离的方式相同),以及将读和写请求分隔到不同队列的RocksDB。所有版本的 RocskDB 都在禁用压缩的情况下运行,因为压缩造成的干扰太大,无法注意到这些更细微的延迟变化。SILK+在启用所有内部操作的情况下运行,因为机会I/O分配和内部操作优先级减轻了压缩干扰。在本实验中,将扫描请求视为多次读取。